AI Citation Hallucinations in Legal Research: The Verification Problem Nobody Has Solved Yet
A lawyer submits a skeleton argument. The authorities look right. The citations are formatted correctly. Opposing counsel starts checking and one of the cases does not exist.
This is not a hypothetical. In 2023, two New York attorneys filed submissions citing cases fabricated by ChatGPT. The judge sanctioned them. The cases were entirely invented, complete with realistic-looking neutral citations and plausible summaries.
That was three years ago. The problem has not gone away. If anything, the volume of AI-assisted drafting has increased, and the verification habits of many practitioners have not kept pace.
Fake citations are now passing academic peer review
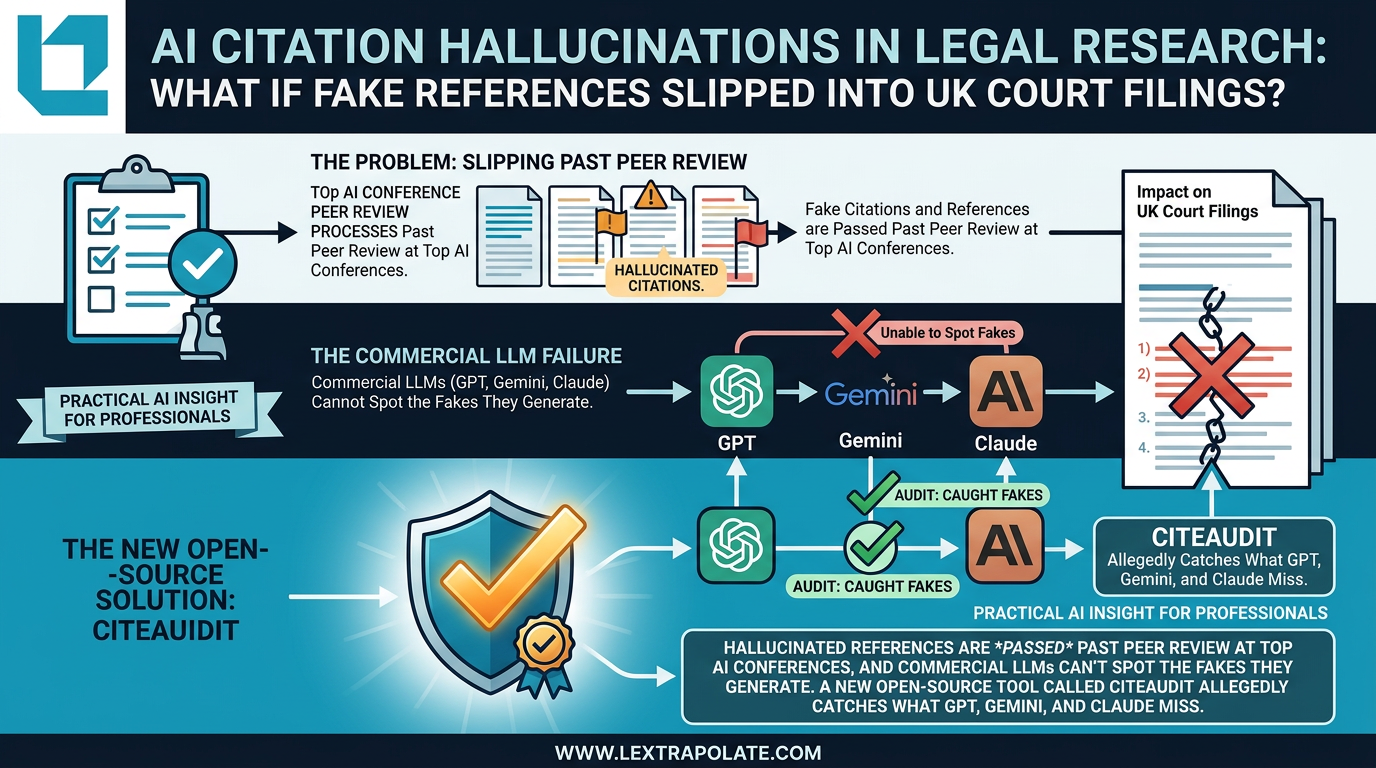
A preprint paper published on arXiv in early 2026 makes a serious claim: hallucinated references are appearing in papers accepted at major AI conferences, and commercial large language models cannot reliably detect the fakes they generate.
The paper introduces CiteAudit, an open-source tool built on a multi-agent pipeline. According to the paper's own benchmark, the tool achieves over 97% accuracy in detecting fabricated citations by cross-referencing against databases including Google Scholar and arXiv, then checking metadata against the claims made in the source document.
That is a striking number. It warrants scrutiny.
The research appears to be a genuine academic contribution rather than a vendor announcement. The tool is open-source and tied to a peer-reviewed preprint. But the benchmark is self-reported. Coverage is currently limited to summaries of the paper itself, and no independent third-party evaluation has emerged. CiteAudit may well perform as advertised. We have not tested it and cannot say. The concept, however, is sound and the underlying problem is real.
The broader finding is what matters: that single LLMs, including GPT-4, Gemini, and Claude, cannot reliably verify the citations they produce. That should not surprise anyone who has used these tools seriously. LLMs predict plausible text. A realistic-looking citation is, to a language model, just another plausible string. Verification requires something different: checking the claimed reference against an external source, confirming it exists, confirming the document says what the citation claims it says. That is a retrieval and comparison task, not a generation task.
The legal risk is specific and serious
In English practice, the consequences of citing a non-existent authority are not abstract. Practice Direction 1A of the Civil Procedure Rules requires parties and their representatives to help the court further the overriding objective. Filing fabricated citations is likely to constitute a contempt of court, and certainly constitutes professional misconduct under the SRA Standards and Regulations.
The SRA has been clear that individual solicitors retain responsibility for AI-assisted work. Competence under Principle 4 does not disappear because a tool produced the draft. If you submit a document, you own it. The Ayinde case, in which a barrister was found unfit to practise partly due to inadequate document management, is a useful reminder that courts and regulators treat sloppy handling of legal materials as a professional failure, not a technical glitch.
The negligence exposure is also real. A solicitor who submits an authority that does not exist, causing delay, costs, or worse to a client, has potentially breached the duty of care in Bolam terms. The standard is that of the reasonably competent solicitor. A reasonably competent solicitor checks their citations. Delegating that check to the tool that generated the citation is not checking.
Barrister readers will know the specific concern on their side of the profession. The cab-rank rule and the duty to the court sit alongside the increasing commercial pressure to turn around skeleton arguments quickly. AI drafting tools accelerate the first draft. They do not reduce the professional obligation to verify what goes on the page.
Why single LLMs cannot verify their own output
It is worth being precise about why asking an LLM to check its own citations fails as a strategy.
When an LLM generates a citation, it does so from patterns in training data. When you ask it to verify that citation, it draws on the same patterns. There is no independent check happening. The model may confirm a fabricated reference with apparent confidence because the reference looks like real references it has seen. This is not a bug that will be patched. It is a structural feature of how these models work.
Effective verification requires a different architecture: extract the citation, query an external database, retrieve the actual document if it exists, compare the claimed proposition against the document's content. That is what multi-agent systems designed for this purpose attempt to do, and it is why specialist tools in this space are worth taking seriously, provided they are independently evaluated.
CiteAudit is one entrant in what is becoming a recognisable category. LawDroid CiteCheck and similar tools are targeting overlapping problems. The field is young and claims should be tested, not assumed. But the category itself represents the right response to a genuine structural problem.
The Monday morning test
If you are using an LLM to assist with legal research or drafting, the practical implication is straightforward.
Do not ask the LLM to verify its own citations. The model that generated the citation cannot reliably check it. Instead, treat every AI-generated case reference as unverified until you have done one of the following: pulled the case yourself on Westlaw, Lexis, or the National Archives; confirmed the pinpoint reference actually appears in the judgment; confirmed the proposition attributed to the case is what the court actually decided.
This is not a counsel of perfection. Experienced practitioners already do this for significant authorities. The problem arises in the middle tier of citations, the supporting cases, the propositions cited as background, the secondary references. These are exactly where hallucinations hide, because they are exactly where the reader is least likely to check.
If a tool emerges that performs this verification reliably at scale, the workflow benefit would be substantial. Until such a tool has been independently evaluated and tested in practice, the responsibility remains with the professional.
The deeper point
The citation problem is a specific instance of a broader truth about AI-assisted professional work. These tools are very good at producing plausible output. Plausible is not the same as correct. For knowledge workers, the value of expertise is precisely the ability to distinguish between the two.
Automation of the drafting task does not reduce the expert's responsibility to check the output. In some ways it increases it, because the volume of output rises and the plausibility of errors increases. A handwritten fabrication looks like a mistake. A well-formatted AI hallucination looks like research.
The firms and practitioners who will do this well are those who treat AI output as a first draft requiring verification, not a finished product requiring formatting. That distinction is professional judgement. It cannot be outsourced to the tool.
The development of specialist verification systems for citations is a welcome step in the right direction. Whether any specific tool delivers what it promises requires independent evaluation. The concept, though, is not optional. It is where responsible AI adoption in legal practice has to go.
Sources
- 1CiteAudit: You Cited It, But Did You Read It? A Benchmark for Verifying Scientific References in the Large Language Model Era
- 2Hallucinated references are passing peer review at top AI conferences and a new open tool wants to fix that
- 3CiteAudit: Benchmark to Detect Fake Citations - YouTube
- 4CiteAudit: You Cited It, But Did You Read It? A Benchmark for ... - arXiv (HTML)
Stay ahead of the curve
Get practical AI insights for lawyers delivered to your inbox. No spam, no fluff, just the developments that matter.
Chris Jeyes
Barrister & Leading Junior
Founder of Lextrapolate. 20+ years at the Bar. Legal 500 Leading Junior. Helping lawyers and legal businesses use AI effectively, safely and compliantly.
Get in TouchMore from Lextrapolate
What If Multi-Agent AI Could Search Three Million PDFs Before Breakfast?
PDFs are still the dominant friction point in legal discovery. Multi-agent AI is changing that fast. Here is what practitioners need to understand now.

What If AI Transforms Hiring Overnight? UK Legal and Ethical Risks as Automated Interviews Scale
AI avatars are conducting job interviews at scale. UK employers using these tools face real legal exposure they may not have mapped yet.
What if the invisible context window is the most important thing you cannot see?
Understanding what the AI actually sees when you prompt it is the difference between controlled output and expensive guesswork.