What if the invisible context window is the most important thing you cannot see?
Suppose your client hands you a brief. You read it, advise on it, draft from it. Now suppose someone had silently removed three pages before you received it, without telling you. Your advice would still sound confident. It would still be wrong.
That is a reasonable approximation of what happens when a lawyer uses an AI tool without understanding the context window.
What the model actually sees
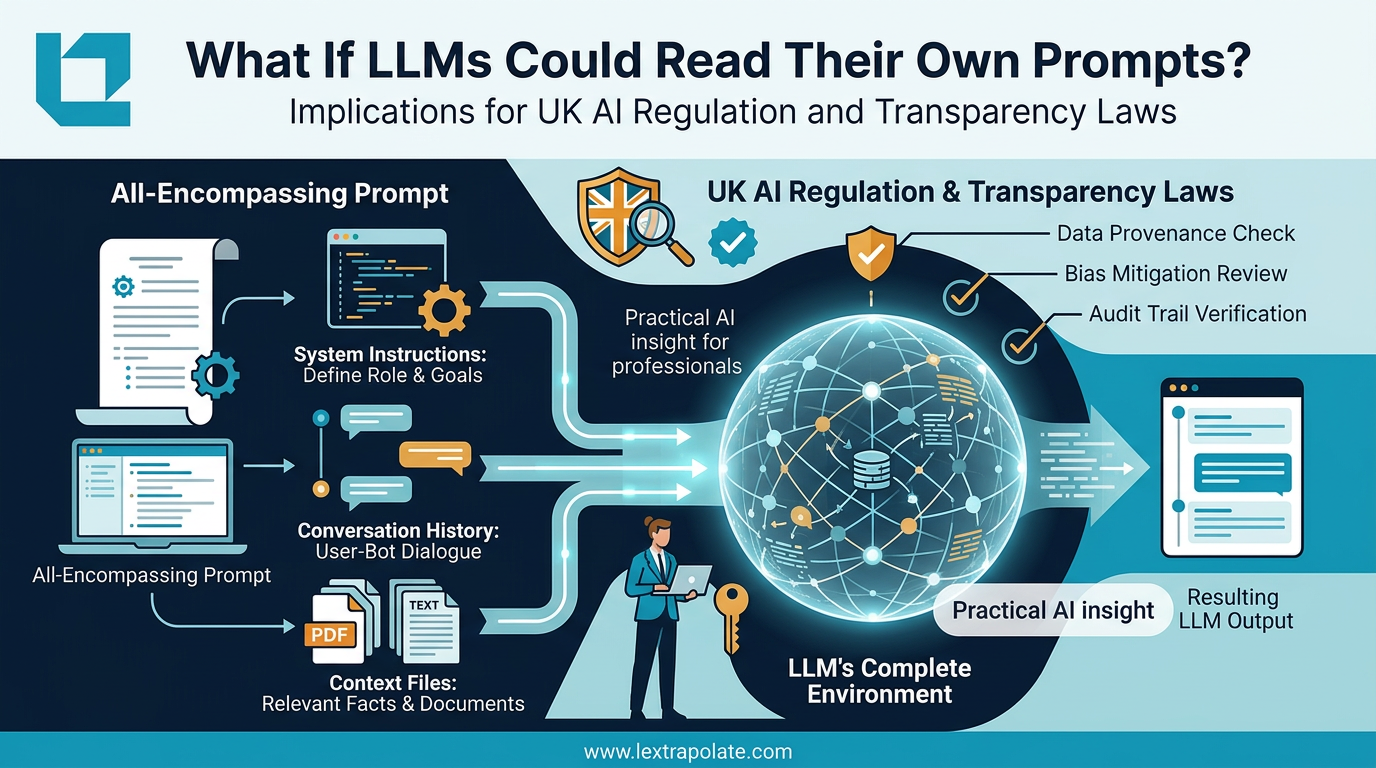
When you type a prompt into a large language model, you are not sending a simple message. You are submitting to a process that assembles your input inside a much larger structure. The model receives, in one combined payload, a system prompt set by the tool or platform developer, the full conversation history of the current session, any documents or context files you or the platform have supplied, and finally your actual question.
That entire assembled payload is the context window. The model responds to all of it. Not just to you.
A piece that circulated on Hacker News captured this with some clarity. An LLM-generated essay, written as an exercise in AI introspection, described the model's own environment in these terms: the output is shaped by instructions the model cannot show you, history it carries silently, and files it has been given. The model does not experience these as separate inputs. They form the totality of what it knows in that moment.
The practical implication is significant. If the platform you are using has embedded a system prompt that tells the model to be conservative, to disclaim, or to refuse certain outputs, your prompting cannot override that. You are working inside a defined space without a map of its boundaries.
The lawyer who thinks they are in control
Most lawyers using AI tools operate under a reasonable but mistaken assumption: that their prompt is the instruction and the model's output is the response. Clean. Bilateral. Controllable.
The reality is that your prompt is one voice in a conversation the model is already having with its own configuration. A well-designed commercial legal AI tool will have a system prompt running hundreds, sometimes thousands, of tokens before you type a single word. That prompt may constrain jurisdiction, tone, output format, or the categories of question the model will engage with at all.
This is not a defect. Thoughtful system prompting is how responsible vendors try to make tools fit for professional use. But it creates a structural information asymmetry. The tool knows more about the rules governing its own behaviour than you do.
For a lawyer, information asymmetry is not an abstract concern. If you do not know what constraints are shaping the output, you cannot assess the reliability of that output. You cannot form a professional view on whether the answer is complete. You are, in effect, advising on a brief with missing pages.
The Ayinde case sits in the background here. A solicitor submitting AI-generated content to a court without adequate verification failed in a professional duty. The root cause in cases like that is rarely that the AI was wrong by accident. It is that the practitioner had no structured method for understanding what the AI had and had not been told to do.
Why conversation history compounds the problem
The context window is not static. It grows with each exchange in a session.
Ask a model three questions in sequence and the fourth response is shaped by all that preceded it. If your early questions established a particular framing or a set of assumptions, those assumptions persist. The model does not flag this. It simply continues to respond within the frame you have jointly constructed.
For legal work, this has a specific risk. A researcher building a long session to analyse a complex commercial dispute may, by the fifth or sixth exchange, have embedded assumptions about governing law, applicable standard, or party characterisation that are never revisited. The model will not volunteer that the initial assumption in question two was subtly wrong and that all subsequent answers reflect that error.
The only discipline against this is deliberate session hygiene: starting new sessions for new questions, explicitly restating key parameters at the start of each exchange, and treating long sessions with the same scepticism you would apply to a witness who has already committed to a version of events.
What you can do
The context window is not fully visible, but it is partially manageable. These are practical steps, not theoretical ones.
Audit the platform you are using. Most serious legal AI vendors publish documentation on how their system prompts are structured, even if they do not reveal the exact text. Read it. Understand the constraints baked into the tool before you use it for substantive work.
Ask the model what it knows. This sounds basic, but it is effective. At the start of a session, ask the model to summarise what instructions or context it has been given. A well-configured tool will tell you what it can. If it deflects or claims ignorance entirely, that is itself useful information about the constraints operating on it.
Supply your own context explicitly. Do not rely on a tool to infer jurisdiction, applicable law, or the specific version of a document you want analysed. State those things at the start. Treat the beginning of each session as a standing instruction, not a preamble.
Treat long sessions with scepticism. If a session has run to ten or more exchanges, the accumulated context may be shaping outputs in ways you cannot easily trace. For high-stakes work, start fresh. Restate your parameters. Cross-check outputs from earlier in the session against outputs from a clean run.
Separate drafting sessions from research sessions. The framing required for good research is different from the framing required for good drafting. Running both in a single session creates blended context that serves neither task well.
The competence question
There is a broader professional point here that does not require waiting for regulatory guidance to land.
Competence in AI-assisted legal work is not simply knowing how to type a prompt. It requires understanding the environment in which that prompt operates. A barrister who does not understand how their instructions were assembled before they received them would not be considered fit to advise on them. The logic extends to AI tools.
The context window is the instruction set you cannot fully read. Your job is not to pretend it does not exist. Your job is to account for it, work around its limits, and verify outputs in the knowledge that the model was operating inside constraints you may not have chosen and cannot entirely see.
That is not a counsel of despair. It is the starting point for actually using these tools well. With training, you can.
Sources
Stay ahead of the curve
Get practical AI insights for lawyers delivered to your inbox. No spam, no fluff, just the developments that matter.
Chris Jeyes
Barrister & Leading Junior
Founder of Lextrapolate. 20+ years at the Bar. Legal 500 Leading Junior. Helping lawyers and legal businesses use AI effectively, safely and compliantly.
Get in TouchMore from Lextrapolate

What If AI Transforms Hiring Overnight? UK Legal and Ethical Risks as Automated Interviews Scale
AI avatars are conducting job interviews at scale. UK employers using these tools face real legal exposure they may not have mapped yet.
AI Citation Hallucinations in Legal Research: The Verification Problem Nobody Has Solved Yet
Fake citations are slipping past peer review at AI conferences. If that's happening in academia, what's the risk in legal practice?

What If a Deepfake Became Your Evidence? The Verification Problem Professionals Can't Ignore
AI-generated images and video are flooding professional workflows. Newsroom verification techniques offer a practical defence for lawyers and knowledge workers.